
Now that we’ve established that we can benefit from combining multiple projection models into one, let’s take a look at the challenges this presents.
I’ll also give brief explanations of how you can work around these challenges in Excel. At the end I’ll discuss an Excel template I’m working on that will do these calculations for you automatically and how you can get your hands on it.
I love Your Feedback
If you’re a SFBB Insider you might recall that after you sign up, the very first e-mail I send you asks you to reply with any fantasy baseball topics you’d like to know more about or difficulties you’re having (if you’re not, you can register here. I like to think it’s worth your while).
I Read All Of Those Responses
I’ve been fortunate enough to have nearly 500 people register, and I read every single response that comes in from that question. One of the most frequent areas of interest is how to average, or aggregate, multiple sets of projections into one usable set of information.
More Difficult Than I Originally Thought
These requests started to roll in during the off-season, and I even replied to several people saying that I thought this was going to be easy and that I’d have guidance coming out soon on how to do this.
… And here I sit months later having never written on the topic yet.
In theory, averaging a set of three numbers in Excel is easy. If one system says 25 HR, one says 30 HR, and another says 35 HR, Excel’s AVERAGE formula can easily respond with the average of 30.
But I quickly ran into some big problems that greatly complicated things.
Problem 1 – Lining Projections Up To Do The Averages
In order to aggregate multiple projection systems into one, we need a method of “lining up” the projections from one system with those of another system. Perhaps Giancarlo Stanton is projected to hit 20 HR the rest of the season by Steamer and 22 HR by PECOTA.

We can use formulas in Excel (e.g. VLOOKUP) to pull Stanton’s Steamer projection and place it next to his PECOTA projection. But you can run into some complications in doing this. What if one projection system lists him as “Stanton, Giancarlo” and the other as “Giancarlo Stanton”.
Using names to pull data also opens you up to inconsistencies in the name being used. Is it Jonathan Singleton or Jon Singleton? AJ Burnett or A.J. Burnett?
If you have taken on the challenge of creating your own rankings, you know that we’ve dealt with this problem before, but on a smaller scale. In my rankings spreadsheets I use a consistent playerID to pull information between the different tabs. I prefer to use the Baseball-Reference playerIDs because you can tell who a player is (Stanton is “stantmi03” because there were two other Mike Stanton’s before him).
But seemingly every major baseball site has their own player ID system. Fangraphs says Stanton is “4949”, Baseball Prospectus uses “57556”, ESPN says “30583”, etc.
This is why I maintain the SFBB player ID map Excel file. The map allows for this translation or “lining up” to happen. It’s the bridge that can easily help you take Stanton’s projection from one system and place it next to his projection from another. 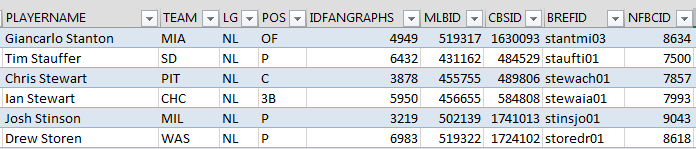
Problem 2 – Players Not Projected In All Systems
So we have a mechanism to pull different projections systems together for each player, everything should be easy from here on out. Right?
For a player like Giancarlo Stanton, yes. Regardless of the projection system you’re using, he’s going to be in it. But what about more obscure players or players currently in the minor leagues. Some systems will create projections for them and others won’t. If you develop your own projections one player at a time, you don’t have time to project into the minor leagues.
How do we deal with this? If you’re careful about your Excel formulas, you can handle it properly. Take this example (image below). There’s a big difference in projecting a player for zero home runs (Hip Minor Leaguer) and not projecting a player at all (Chic Minor Leaguer).

You can see that Excel’s AVERAGE formula will exclude an empty cell from its calculation. This is good. We don’t want the fact that a player is not projected by a system to artificially drag down their aggregate projection.
If a player is not projected by a particular system, you’ll quickly run into a problem using VLOOKUPs. If Excel can’t locate a player’s name or PlayerID in the projections, it will return the ugly “#N/A” error. And the AVERAGE formula won’t know what to do with that either (how do you calculate the average of 10 plus “#N/A”?).
This brings us to the IFERROR formula, which is a nifty workaround to use when you’re encountering errors like this in Excel. You can read more about the specifics of using IFERROR here. But this formula will let us turn all of those “#N/A” error messages into anything we choose.
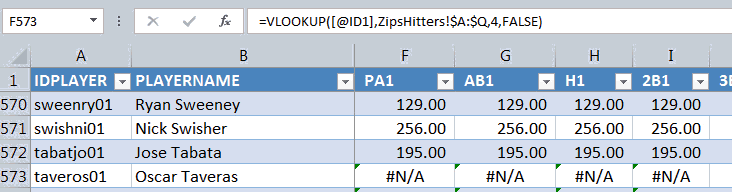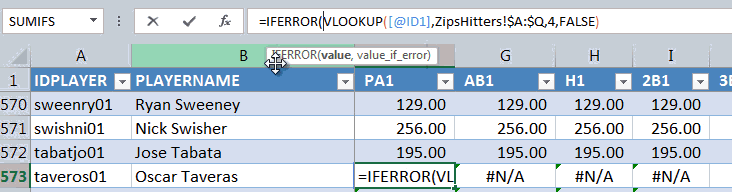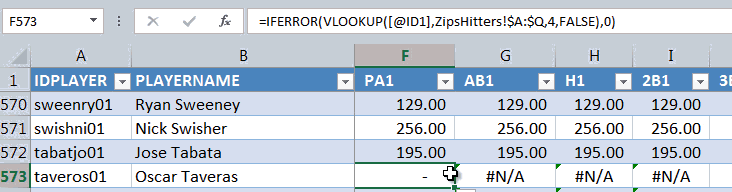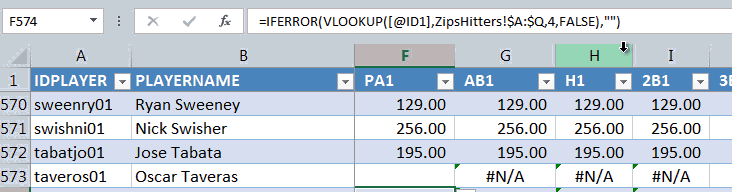
As we discussed above, we don’t want these “#N/A” messages to turn into zeroes. We want the cells to be blank (in some scenarios you may want zeroes, in some you may want blanks, so I demonstrate both in the image above).
To get IFERROR to return a blank cell value we can use “” (double quote, double quote).
Problem 3 – Some Systems Don’t Project Playing Time
Take Oliver for instance. Every player is projected for 600 PAs.
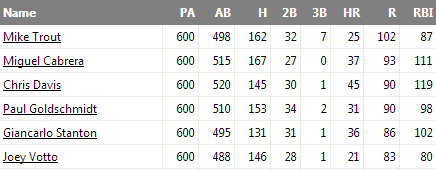
We could just ignore Oliver because of this oddity, but we might be missing out on a valuable opportunity. After all, Oliver is a credible system published by Brian Cartwright and the Hardball Times. It incorporates weighted averages of previous seasons, aging factors, and regression. But it also uses a different approach for projecting minor league players and does a better job of projecting how those minor leaguers will fare in the Major Leagues.
In the last discussion of why using multiple projection systems is beneficial, one of the key principles behind this is that you use forecasts that have different approaches. This results in the highest level of accuracy.
So Oliver makes no attempt at projecting playing time. Some systems (like Steamer) seem to do a good job of incorporating recent news and events into playing time estimates. And others probably try to project playing time, but don’t go to that same level of effort.
So what are we to do?
Instead of ignoring systems that are bad at it (or don’t try), we can take playing time estimates from those systems that are good at it and use only the Plate Appearance or Innings Pitched estimates from those system.s
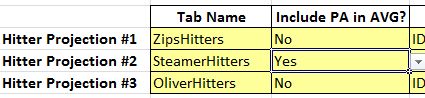
Then we can convert all the other projections into playing-time-neutral measures (HR/PA, AB/PA, RBI/PA, SB/PA, etc.). We can then average or aggregate these playing-time-neutral measures and then multiply those measures by our playing time estimate.
For example, let’s assume we have three different projection sets. We do some math to calculate the per-plate-appearance values for each stat. And these three systems estimate that Giancarlo Stanton will hit 0.056 HR/PA, 0.060 HR/PA, and 0.060 HR/PA, respectively. We average these playing-time-neutral numbers together to get 0.0587 HR/PA (or about 35 HR / 600 Plate Appearances).
We can take this 0.0587 HR/PA number and then multiply it by an independently calculated playing time estimate. This translation process allows us to use any projection system, even if it’s terrible at projecting playing time.
Problem 4 – I Wanted To Input My Own Playing Time Estimates
I have not studied if I’m any good at this or not, but if there’s one part of projecting statistics that I do want control over, it’s the ability to manually override playing time estimates with my own.
A projection may say Troy Tulowitzki will miss more time than I think. Maybe I want to draft Bryce Harper as though he’ll stay healthy this year. Perhaps I think a fourth outfielder will find a way into a full-time role early in the season. Or maybe news comes out that a player will miss three months of the season right before the draft.
I don’t think I can project statistics better than PECOTA, Steamer, or ZiPS. But I want the ability to put in my own playing time estimates for the situations like those described above.
The great thing is that by putting all the projections in the neutral context described in Problem 3, it’s easy to allow for this.
Let’s assume I’ve set up a rest of season projection for Troy Tulowitzki and it calculates that he’ll get 263 plate appearances the rest of the way. If I find out he’s come down with a groin injury and is about to hit the DL, I want the ability to override his estimate downward.
![]()
I can use Excel’s “IF” formula to detect if I have given a value in the “OVERRIDE PA” column. If there is no override, I want the average of plate appearances from the other projection systems. If there is an override, I want the override to be used as my plate appearance estimate.
![]()
Problem 5 – Weighting Systems Differently
When researching the concept of aggregating multiple projections into one, a suggestion I came across was that you should not weight systems differently unless you had a really good reason to do so. Maybe you studied the different systems over time and you mathematically have found an ideal weighting that you want to use.
I’m probably not going to take my work to that level. But I could see this as something people would want. If you’ve ever read an article about the accuracy of baseball projections, the article inevitably will go in this direction and talk about what the ideal weighting would be.
Another interesting application is that some projection systems, like Marcel, are simply different weighted averages of previous seasons. So by building in a simple weighting system, a projection averaging model could do something like this.
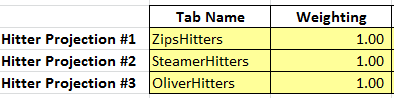
So I sought out to tackle this problem too. Any projection averaging tool should allow for equal weighting:
Or unequal weighting:
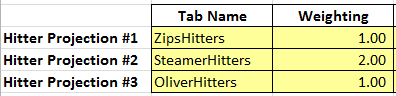
And then the playing-time-neutral projection calculations would calculate the weighted average based upon these assigned weights.
The Solution…
I have developed an Excel file that addresses the problems above. You just need to copy and paste Excel or CSV formatted projections into the Excel file, make sure the PlayerID is in the first column of the data, and then enter a few pieces of information:
- The name of the tabs you brought in (containing your projections)
- The column range on the tabs you brought in (for example “A:X” if the projection data goes from column A to column X)
- Provide a weight for the projection (as described above)
- Answer a Yes/No question on if you want playing time (PA or IP) for each projection included in the average playing time calculation
- And select the PlayerID for the projections you have brought in (Fangraphs ID, Baseball Prospectus ID, Baseball-Reference ID, etc.)
I think you can realistically have averaged projections in under 10 minutes. No complicated formulas. No dealing with the issues above.
There are a few things I think you should know
- I think you should have at least Microsoft Excel 2010 to use this file. It may work on Excel 2007.
- You need Windows. I don’t think this will work on Excel for Macs.
- This does not rank or calculate dollar values for players. You could add your own calculations around the projections though.
- Depending on the speed of your computer, the file can be slow. The formulas in the Excel file are complicated and they can take up a lot of your computer’s resources.
This Sounds Great. How Do I Get My Hands On It?
Because the formulas in the file are complex, I’m not yet 100% certain (maybe 90-95%) that everything is working correctly. I’m looking for some help in testing the accuracy, making sure it’s easy to use, and help in identifying things that are confusing or need clarification.
My plan is to e-mail the SFBB Insiders within the next couple of weeks to look for a group of about 25 people interested in seeing this template first.
If you’re not already registered, now would be a great time to sign up!
UPDATE: The testing has already begun, but you can still sign up and get you hands on the next prototype.
Thanks For Reading
If you have any other ideas for tools you’d like to see or advice on challenges you’re facing, don’t hesitate to contact me. I may not have an answer right away (like the months it took me to finish this averaging project), but I’ll get there eventually. Slow and steady…
Stay smart.






