The SFBB Excel tools are updated and ready to help you prepare for the 2024 season! If you’re looking to build skills and develop your own methods for ranking and valuing players, these are for you!
The Automated SGP Ranking Tool will help you convert your favorite projection set (Steamer, The Bat, Razzball, RotoWire, PECOTA, etc.) into Excel-based rankings and dollar values tailored to your own league’s settings. The process takes only minutes. No messy Excel formulas. Just load your projections into the file, adjust a few settings, and standings gain points rankings are calculated automatically. Click here to read more about the tool.
Powered by the same concepts as the Automated SGP Ranking Tool, the Automated Points League Ranking Tool does all the same things, just for nearly any imaginable points league. The tool works with any popular projection set and allows you to enter your league’s unique point scoring system, then instantly converts those projections into tailored point totals and dollar values. The process take minutes and will give a huge advantage over owners that are not tailoring rankings specifically to the league scoring system. Click here to read more about the points league tool.
An easy-to-use Excel spreadsheet that can combine (or average) up to five different projection sets. The aggregator can use just about any well-known projection set you can find on the web (if you find one that doesn’t work, let me know!). Simply download your favorite projection sets, fill out some settings, and you’re done. No complicated formulas or VLOOKUPS for you to add.
I had the opportunity to make a guest appearance on two of my favorite podcasts in the last several months. Read below for details and links to listen.
Baseball HQ Radio with Patrick Davitt (September 16, 2022)
I discuss this a little during the interview with Patrick, but when I first started this website and was trying to immerse myself in different opinions and tactics for playing rotisserie, Baseball HQ Radio was a huge help in learning and improving. I went so far as to listen to all the old interviews as far back as my podcast player would go. I believe the format of the podcast has change slightly over the years, but the guest interviews with teachers and unique thinkers like Ron Shandler, Gene McCaffrey, Triston Cockroft, Mike Gianella, Todd Zola, and many others were helpful at forming my approach.
Even though the podcast took place while the 2022 season was still ongoing, as with much of my content, I try to keep things pretty evergreen and always relevant. We discuss a lot of strategy and fantasy baseball philosophy, along with some break down and conclusions from the 2022 season.
It was an honor to make an appearance on this show. HQ Radio is legendary and one of the longest running podcasts around.
The episode runs over three hours, but my segments all fall within the first half of the show.
PullHitter Fantasy Baseball with Rob DiPietro (January 13, 2022)
Welp. If you thought the HQ podcast was eventful, this may have topped it. Rob (2020 NFBC Draft Champions winner) lined up to have me, Jeff Zimmerman, Steve Weimer (2nd and 6th overall in 2022 NFBC Main Event), Phil Dussault (2021 NFBC Main Event, NFBC Auction Championship winner and 2021 Online Championship runner up), and Toby Guevin (multiple time NFBC Main Event and high stakes league winner). I don’t think this much NFBC success has been on one podcast before.
This conversation covered a wide range of topics and interesting discussions, ranging from The Process to how the group is handling the MLB rule changes, as well as some very interesting strategy and process discussions about topics like aggregating projections and how managers should best spend their time
I will note that I really enjoy listening to Rob’s podcast and how he takes the individual interviews with fantasy managers to the next level of depth. Some folks object to very lengthy podcasts, but I think that’s the beauty of the medium. There’s no way to uncover a lot of the details that Rob is able to by forcing an interview to fit within a tight window. The conversation here does ramble at time, but then there are some truly valuable nuggets and discussions that wouldn’t have surfaced if we had followed a more structured format.
Below you’ll find the link to the podcast as well as a snippet Rob created from some of my commentary.
The SFBB Excel tools are updated and ready to help you prepare for the 2023 season! If you’re looking to build skills and develop your own methods for ranking and valuing players, these are for you!
The Automated SGP Ranking Tool will help you convert your favorite projection set (Steamer, The Bat, Razzball, RotoWire, PECOTA, etc.) into Excel-based rankings and dollar values tailored to your own league’s settings. The process takes only minutes. No messy Excel formulas. Just load your projections into the file, adjust a few settings, and standings gain points rankings are calculated automatically. Click here to read more about the tool.
Powered by the same concepts as the Automated SGP Ranking Tool, the Automated Points League Ranking Tool does all the same things, just for nearly any imaginable points league. The tool works with any popular projection set and allows you to enter your league’s unique point scoring system, then instantly converts those projections into tailored point totals and dollar values. The process take minutes and will give a huge advantage over owners that are not tailoring rankings specifically to the league scoring system. Click here to read more about the points league tool.
An easy-to-use Excel spreadsheet that can combine (or average) up to five different projection sets. The aggregator can use just about any well-known projection set you can find on the web (if you find one that doesn’t work, let me know!). Simply download your favorite projection sets, fill out some settings, and you’re done. No complicated formulas or VLOOKUPS for you to add.
This year’s edition of The Process contains many exciting new updates, studies, standings, and SGP data. Visit thefantasybaseballprocess.com to read many more details.
I heard this on a podcast recently. Can’t remember which one. So, I can’t give credit. It’s also not the first time I’ve heard the phrase. Maybe I shouldn’t worry too much about it.
I agree with this statement. But since I’m a natural contrarian (ask my wife) my knee-jerk response is, “Yeah, but there aren’t an infinite number of ways to win.”
I think about this a lot. Probably too much. Maybe the thoughts that follow are obvious. Or maybe I have some unique insight to share. So here goes. Besides, I haven’t written a true blog post in a long time. Buckle up.
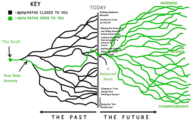
Seeing this Tweet is what ultimately pushed me over the edge to write this:
We think a lot about those black lines, forgetting that it’s all still in our hands. pic.twitter.com/RSZ1d3W642
I’ll agree with the author here. In life we think a lot about those black lines. We tend to be backwards looking. Either relishing in the past or wallowing in it. The Stoics would want us looking at the green path into the future and all the possibilities that exist. But we like to be crippled by bad decisions and feel sorry for ourselves.
I may well be wrong, but I get the impression that most of us are the opposite in playing fantasy baseball. We have to be inherently forward looking. The stats accumulated in the standings can’t be changed. They are what they are. We have no choice but to pull up the free agent listing and plan for the future.
We talk about the future all the time. We are always “preparing”. Projections, prognostications, adding players for the future, dynasty leagues, pursuing a championship. It’s all forward looking.
Maybe that’s why we like this game? Is it inherently optimistic?
Anyways, we fake baseball players tend to forget our past decisions. I’m here to be negative and bring us back to all of our horrible decisions!!!
That’s not really my intent. Some good retrospection and review is good at the end of the season. But I’m not proposing we start looking in the rotisserie rearview mirror any more than that.
I do think the image is insightful and helpful at demonstrating a key bit of strategy I try to always bring myself back to… Stay balanced.
I’ll go as far as to say this is my guiding principle in playing rotisserie (it’s not so relevant for points leagues). I use it any time I’m struggling with a decision. Should I take a pitcher or a hitter? Should I take speed or power? Do I take my third outfielder or my first catcher?
We discuss the topic in The Process but don’t beat the reader over the head with it. I’m about to beat you over the head with it.
Stay balanced!
The phrase is purposely ambiguous. It can mean so many things, all of them helpful. Here are some examples:
Don’t allow yourself to get backed into a corner. Keep your team balanced in both pitching and hitting. Keep a balance across statistical categories. Avoid putting yourself in a situation where you can’t take advantage of good fortunes that come your way. If you are out of balance, needing pitching, and an amazing hitter falls in the draft your decision point becomes getting even further out of balance or passing up the opportunity.
Balance the risk and uncertainty on your roster. Don’t be too risky. Don’t be too conservative or risk averse (BTW, if you say “risk adverse” and you’re a podcaster, I have shaken my fist at you before). You don’t want to be the manager rostering Oneil Cruz, Adalberto Mondesi, and Justin Verlander. You also don’t want a team full of Randal Grichuks and Mark Canhas. There is value in pursuing upside and floor. Both serve a purpose.
I’ve been getting out of my comfort zone of late and have recorded several podcasts since the 2021 season ended. Read below for details on the various podcasts and how to listen.
Justin Mason’s TGFBI Podcast (October 5, 2021)
I was lucky and fortunate enough to win the TGFBI overall championship, out of 435 fantasy baseball analysts. Justin guides me through an interview breaking down my draft, in-season moves, and strategies I used to win the prize.
Launch Angle Podcast with Jeff Zimmerman, Rob Silver, and Van Lee (December 11, 2021)
I joined Jeff, Rob, and Van to discuss the release of the 2022 edition of The Process, as well as to do some ADP player analysis. You’ll get a little peak into my brain and how I go about analyzing a player’s draft price.
On the Wire Podcast with Adam Howe, Kevin Hastings, and Jeff Zimmerman (December 26, 2021)
This was a fun one. We spend much more time talking about The Process, strategy, advice, and how I think about topics like SGP, using projections, and analyzing late-late-late-round players in a format like the NFBC Draft Champions.
The SFBB Excel tools are updated and ready to help you prepare for the 2022 season! If you’re looking to build skills and develop your own methods for ranking and valuing players, these are for you!
The Automated SGP Ranking Tool will help you convert your favorite projection set (Steamer, The Bat, Razzball, RotoWire, PECOTA, etc.) into Excel-based rankings and dollar values tailored to your own league’s settings. The process takes only minutes. No messy Excel formulas. Just load your projections into the file, adjust a few settings, and standings gain points rankings are calculated automatically. Click here to read more about the tool.
Powered by the same concepts as the Automated SGP Ranking Tool, the Automated Points League Ranking Tool does all the same things, just for nearly any imaginable points league. The tool works with any popular projection set and allows you to enter your league’s unique point scoring system, then instantly converts those projections into tailored point totals and dollar values. The process take minutes and will give a huge advantage over owners that are not tailoring rankings specifically to the league scoring system. Click here to read more about the points league tool.
An easy-to-use Excel spreadsheet that can combine (or average) up to five different projection sets. The aggregator can use just about any well-known projection set you can find on the web (if you find one that doesn’t work, let me know!). Simply download your favorite projection sets, fill out some settings, and you’re done. No complicated formulas or VLOOKUPS for you to add.
This post is intended to be an all-encompassing discussion of the Player ID Map tool. Click the links below to jump directly to a specific section below. Use the Back browser or mouse button to jump back to this list.
The MLB and fantasy baseball landscapes are wide reaching. We fantasy players gather information, projections, and opinions from many locations. Any time you have a situation like this, where data is coming from many disparate places, some form of “mapping” table can help connect the dots and data points from these different sources.
If you’ve ever tried to line projections from Fangraphs up with projections from Baseball Prospectus, Mastersball, or Baseball HQ, you’ll understand this challenge. You may have tried a VLOOKUP in Excel or Google Sheets to line the data up side-by-side. But player names are not a great mechanism to do this. Names can change (see Nick Castellanos and Nicholas Castellanos or B.J. Upton and Melvin Upton). Name conventions can differ between sites (see A.J. Pollock and AJ Pollock or Ronald Acuna and Ronald Acuna Jr.). Even worse, there are occasionally duplicate names (Chris Young being a recent example).
The Player ID Map solves these discrepancies. It enables an owner to line up an A.J. Pollock in their spreadsheet to an AJ Pollock from projection system. The Player ID Map is the bridge that has enabled me to build tools like the Projection Aggregator and the Automated SGP Ranking Tool. It enables building spreadsheet tools and other solutions that can work with or link to major sports websites (ESPN), projection systems (Steamer, Razzball, Mastersball, ATC), and fantasy baseball providers (NFBC, Fantrax, Yahoo!, Draftkings).
What Versions of This Tool are Available?
All the different “versions” below are pointing to the same source information. They are just different formats of using or viewing the data.
Excel Version (LINK) – A downloadable Excel file that can be incorporated into your own fantasy baseball spreadsheets. The data in this file contains connections to the main version I maintain in an online Google Sheet. This version will likely be out of date when it is downloaded, but instructions on how to refresh the data through the connection to the Google sheet are easy-to-follow and are included later in this post. The Excel version contains two tabs:
PLAYERIDMAP – All available IDs and naming system information that I track
Change Log – Explanations of changes made, including additions, corrections, and dates these changes were made
Web Version of PLAYERIDMAP (LINK) – A live look at the html/web-based version of the PLAYERIDMAP tab in the live Google Sheet. You might use this if you just want to see the Player ID Map or look for specific pieces of information
CSV Version of PLAYERIDMAP (LINK) – A one-time CSV download of the Player ID Map tab of the live Google Sheet. I wouldn’t really recommend using this because there is no connection back to the live data I maintain, like in the Excel version. But it could be used if you only need an easy-to-use one-time dump of the data.
Web Version of Change Log (LINK) – A live look at the html/web-based version of the Change Log tab in the live Google Sheet. This could be used to review recent changes to the central Sheet and determine if a refresh is needed.
CSV Version of the Change Log (LINK) – I have no idea why I make this available. Seems like it wouldn’t be valuable at all! But it’s here if you need it. It’s a one-time CSV download of just the Change Log tab.
How Do I Update or Refresh the Player ID Map?
Note, you will be prompted about the potential danger of downloading Excel files from the internet the first time you download and open the Player ID Map. There are no dangerous macros or harmful code embedded in the file. It does maintain a connection back to my Google source file to enable you to download updated information. Click “Enable Editing” to accept this reminder and be able to interact with the Excel file.
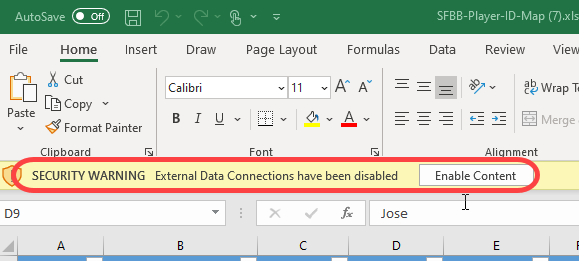
You may at times also see an Excel warning that external data connections can be harmful. These are common warning messages and good reminders that you do have to be careful what you download on the web. Click “Enable Content” to allow the data connection to pull in refreshed player ID data.
If you trust me and do download the Excel file, here’s how to refresh it.
Step
Description
1.
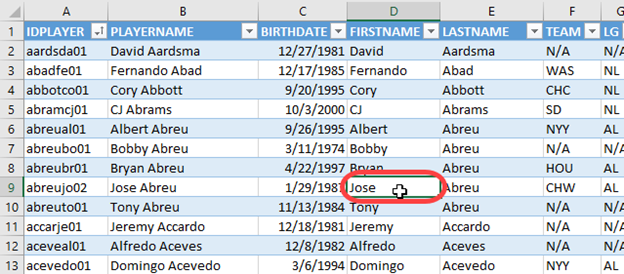
Select a cell inside of the player ID data. It does not matter which player or piece of data. It just has to be something inside the blue and white table.
2.
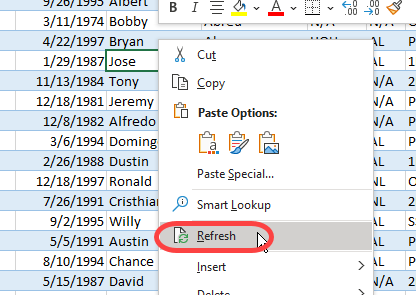
Right-click on the selected cell and choose the menu option to “Refresh”.
3.
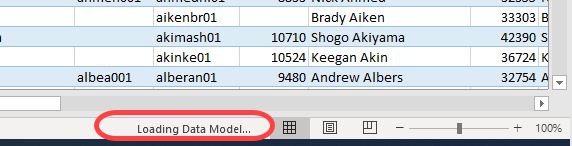
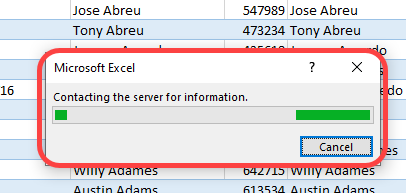
You will begin to see various status messages as Excel begins to refresh the connection. You may see information being relayed in the bottom right of Excel.
A popup may appear. And status information may even appear in the bottom left of Excel (I couldn’t grab a screenshot quick enough).
The entire refresh may take 60 seconds or so. And it may depend on how much time has transpired since your last update. You don’t really get a “This is Done!!!” message. You’ll just know you’re ready to proceed when all the statuses stop changing.
Origin
I created the Player ID Map in 2013. I started my ID map largely from information from Tim Blaker’s map. Tim continues to provide updates in his mapping file, but our maps have different purposes. I needed the flexibility to add new names and systems and not be reliant upon someone else. But I continue to use Tim’s map as an input to mine when I’m performing major updates for new players that enter the baseball world.
The Player ID Map has grown since 2013. I continue to add new systems, new name formats, and even new information about each player that will help me provide spreadsheet tools the the SFBB audience.
Do People Really Use This Thing?
I’m surprised at how often it’s used. At the time I write this article, the file has been downloaded or refreshed over 280,000 times (Who knows. 200,000+ of them could be me tinkering in spreadsheets). If I could only figure out a way to charge ten cents each time it’s used…
It’s an integral part to building long-lasting and flexible fantasy baseball spreadsheets that can take advantage of many different sources of baseball data.
Does the Player ID Map Include All MLB Players?
No. The tool is intended to be used for fantasy baseball purposes. Accordingly, the goal is to include only “fantasy relevant” players. That’s a purposely vague threshold. In the preseason, I generally keep the top 750ish players accordingly to NFBC ADP included in the Player ID Map. This should be enough players to cover most normal leagues. It’s possible the Player ID Map will not be deep enough for your 20-team NL-only league, your AL Central-only league, or your middle-reliever contest. Keep reading for advice on how to get more players added to the Player ID Map.
Looking to get a jump on the 2021 season? Here are the Excel tools and books that are updated and ready to help you prepare for the upcoming season. If you’re looking to build skills and develop your own methods for ranking and valuing players, these are for you! All of the spreadsheet tools listed below have been updated for the 2021 season.
We are sorry to announce that there will not be major updates to The Process for the 2021 edition. Among other things, the shutdown and restarting of the season, the rule changes, the odd schedules, and the seven-inning games would have us questioning the validity of any innovative research.
With that in mind, we’ve decided to offer two editions this year, so our readers can choose the version that’s right for them.
2021 Appendix Edition (PDF) – $7.99
This is the edition for owners that have previously read the 2020 edition and are now looking for updated 2021 appendix data. This slimmed-down version contains just the 65-page appendix containing SGP analysis, Steamer projections, standings data for 2018-2020, and Jeff and Tanner’s thoughts on how to use the standings data from the 2020 season. Click here to purchase the Appendix Only 2021 Edition in a PDF e-book format for $7.99.
Full 2021 Edition (PDF) – $17.99
If you have not previously bought the book, this is the edition for you. The body of this book is the same as the 2020 edition, with an updated appendix. The appendix is updated for various leagues’ standings gains points (SGP), 2021 Steamer projections with the SGP, projected handedness splits, and others. Click here to purchase the Full 2021 Edition in a PDF e-book format for $17.99.
The Automated SGP Ranking Tool will help you convert your favorite projection set (Steamer, The Bat, Razzball, RotoWire, PECOTA, etc.) into Excel-based rankings and dollar values tailored to your own league’s settings. The process takes only minutes. No messy Excel formulas. Just load your projections into the file, adjust a few settings, and standings gain points rankings are calculated automatically. Click here to read more about the tool.
Powered by the same concepts as the Automated SGP Ranking Tool, the Automated Points League Ranking Tool does all the same things, just for nearly any imaginable points league. The tool works with any popular projection set and allows you to enter your league’s unique point scoring system, then instantly converts those projections into tailored point totals and dollar values. The process take minutes and will give a huge advantage over owners that are not tailoring rankings specifically to the league scoring system. Click here to read more about the points league tool.
An easy-to-use Excel spreadsheet that can combine (or average) up to three different projection sets. The aggregator can use just about any well-known projection set you can find on the web (if you find one that doesn’t work, let me know!). Simply download your favorite projection sets, fill out some settings, and you’re done. No complicated formulas or VLOOKUPS for you to add.
Looking to get a jump on the 2020 season? Here are the Excel tools and books that are updated and ready to help you prepare for the upcoming season. If you’re looking to build skills and develop your own methods for ranking and valuing players, these are for you! All of the spreadsheet tools listed below have been updated for the 2020 season.
Co-authored with Jeff Zimmerman, this is our comprehensive guide of the process we use to succeed during a fantasy baseball season. From preseason preparations, the draft, and all the stages of the season, it’s everything we know about playing this game. The book is available in a PDF e-book for $17.99 here or in paperback form at Amazon here.
You can read a comprehensive writeup of all that’s included in the book here, including the foreword by Clay Link, the full table of contents, and testimonials by fantasy analysts like Rob Silver, Rudy Gamble, Eno Sarris, Mike Podhorzer, and Mike Gianella.
The Automated SGP Ranking Tool will help you convert your favorite projection set (Steamer, The Bat, Razzball, RotoWire, PECOTA, etc.) into Excel-based rankings and dollar values tailored to your own league’s settings. The process takes only minutes. No messy Excel formulas. Just load your projections into the file, adjust a few settings, and standings gain points rankings are calculated automatically. Click here to read more about the tool.
Powered by the same concepts as the Automated SGP Ranking Tool, the Automated Points League Ranking Tool does all the same things, just for nearly any imaginable points league. The tool works with any popular projection set and allows you to enter your league’s unique point scoring system, then instantly converts those projections into tailored point totals and dollar values. The process take minutes and will give a huge advantage over owners that are not tailoring rankings specifically to the league scoring system. Click here to read more about the points league tool.
An easy-to-use Excel spreadsheet that can combine (or average) up to three different projection sets. The aggregator can use just about any well-known projection set you can find on the web (if you find one that doesn’t work, let me know!). Simply download your favorite projection sets, fill out some settings, and you’re done. No complicated formulas or VLOOKUPS for you to add.
Ever wanted to create your own rotisserie rankings? This is my instructional guide written specifically to show you how to create customized rotisserie player rankings, dollar values, and inflation dollar values, in Microsoft Excel, tailored to your own league. No more downloading rankings from the web, hoping they apply to your unique league. 10, 12, or 15-team league? $260 or $300 budget? AL-only or mixed league? 10 hitters or 14? It doesn’t matter. This book will guide you through the process of developing rankings for just about any kind of rotisserie league.
My step-by-step guide to building custom rankings, dollar values, and inflation dollar values, in Microsoft Excel, for your points league. This book will guide you through the process of developing rankings for just about any point-based scoring format.
This year’s edition of The Process is now available!
About the Book
A very thorough and detailed write-up of what’s included in the book is available here. At a high level, this book is everything Jeff Zimmerman and I know about how to play rotisserie baseball (and even points leagues). Regardless your level of experience, I guarantee it includes pages and pages of unique ideas, research, and data you have never seen before. We continue to pour our new ideas, new research, and recent realizations into it. The e-book is 265 pages and includes 58 additional pages of appendices full of projections, statistics, and helpful information.
The paperback edition of the book can be purchased from Amazon.com by clicking here.
Keep reading for details on all that was added to this 2020 edition, but my favorite addition is a detailed study that performed on the 2018 NFBC Main Event, including all the player adds, player drops, and final standings of all 34 leagues and 510 teams. The study sought to confirm if the advice and strategies in the book can be observed and corroborated in the actions of the game’s best managers. The NFBC Main Event, with its $1,700 buy in, prestigious name, and overall competition aspect, offers the best laboratory to study this.
That new study delves into many topics:
How much does draft position affect the chances of winning a league?
Do better owners just accrue more playing time? Or are their players also accumulating more stats per AB and per IP? How much more?
How many free agent transactions do the best teams make?
How do these better owners spread their transactions throughout the season?
How do these better owners allocate their FAAB spending?
What bidding patterns can be observed from winning teams?
How do these owners allocate transactions between hitters and pitchers?
How often do these owners acquire two-start pitchers? Closers?
How much season-long value do these owners acquire and drop during the season?
How much weekly value do these owners acquire and drop during the season?
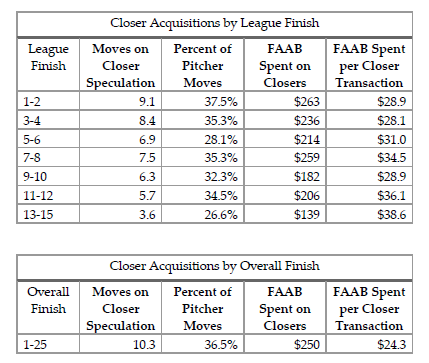
For example, here’s a table of data in the section analyzing how owners finish in the standings and the amount of moves spent on closer speculation.
Closer acquisitions in the 2018 NFBC Main Event.
A Personal Note
I’m really proud of this book. Or shall I say, this annual publication that we’ve started. But the intent to have annual editions creates a significant challenge. The book’s main strength is its long-term nature. Much of what we discuss are fundamental concepts to success at rotisserie baseball. Those ideas are not going to change much from year-to-year. It’s certainly going to be a test to keep the book relevant and worthy of your time and money. We understand that.
I am confident we can do this. Afterall, I’ve been writing on this site for several years now, exclusively with a long-term slant to my analysis. I don’t have much time to write. So I choose to focus my efforts doing research, writing instructions, and building tools that will have long-term benefits. I simply don’t have time to devote to writing short-term pieces that will be irrelevant within weeks or even days. Despite blogging for several years and having written a handful of books, I still feel as though we’re finding new ways to play and think about rotisserie baseball. I see no shortage of strategy-related questions to research.
You can see this in the topics we expanded in this year’s book. Among the higher-level strategy questions approached in this year’s book are:
Are rookies more volatile than established hitters? Does a rookie’s upside offset the possible downside? Do rookie projections differ from the projections of MLB regulars?
How much does a player’s previous levels of fantasy-production affect their future performance? Do these players offer a higher return on investment than those that have never before attained a given production level?
What are the key differences owners should know about the SGP and z-score player valuation models? Where are these systems similar?
How does the cost of closers during the draft compare to their cost in free agency (FAAB)? How does the cost of starting pitchers differ?
How much value should multi-position eligibility add to a player’s valuation? (Note: This topic was included last year, but we expanded our thoughts)
Having studied how weekly values appear in 12-team leagues during the 2017 season, how much did things change in 2018? How does the appearance of weekly values change in a 15-team league?
What do average weekly statistics lines look like for players? For example, what does a $30-35 weekly hitter line look like? What do valuable weekly pitcher statistics look like?
What strategies and behaviors can we observe from the NFBC’s amazing data (standings, adds, drops, etc.)? What behaviors lead to success? What beliefs about how to best play rotisserie baseball can we confirm by studying this data?
On top of all this, Jeff and I continue to evolve the way we play the game and we share those changes and decisions with you. Here are the new discussions of strategies, tips, and tools included this year:
We co-owned a team together this season. We share what we learned from this experience, both during the draft and in-season. Our general recommendation is that partnering is very helpful, especially for leagues where there is a grind of weekly transactions.
To that end, we outline the weekly FAAB process we went through together on that shared league. Having a consistent weekly routine is the key to uncovering valuable players and to avoiding under- or over-bidding. We share the process that works for us.
We outline the specific tools we use to identify FAAB targets and two-start pitchers. We also share the process we go through for setting lineups and finding important last-minute MLB news.
We explored different approaches to dealing with catchers this past season. We share the results of those strategies.
We share a FAAB binning strategy that helps owners stay disciplined about overbidding and maintaining a healthy weekly budget.
Do you have to read through the entire book hunting for what’s new? No! We kept track for you. You can see a full list of changes and jump right to the updated content. Here’s what that list looks like.
Please Click the ‘Buy Now’ Button Below to Purchase the e-Book for $17.99
After clicking the “Buy Now” button, you’ll be taken through an online checkout process using PayPal. There is also an option to pay with a debit or credit card. After completing the purchase, a link to download the PDF book will immediately be e-mailed to you. You can read the PDF on any mobile device, PC, or tablet.
Or Click Below to Buy the Paperback Edition at Amazon for $22.99
“The Process”, My Latest Book, with Jeff Zimmerman
The 2024 edition of The Process, by Jeff Zimmerman and Tanner Bell, is now available! Click here to read what folks like John Pausma, Phil Dussault, Eno Sarris, Clay Link, Rob Silver, Rudy Gamble, and others have to say about the book.
The Process is your one-stop resource for better drafting, in-season management, and developing strategies to become a better manager. The book is loaded with unique studies, tips, and strategies you won't find anywhere else. Click here for more details.